仾偙傟偼奜偟偨梊憐偱偡丅抪傪偝傜偡偨傔偵椺偲偟偰偲傝偁偘傑偟偨丅梸挘偭偰曃岦偑偐偐偭偰偄傞偙偲偑傛偔暘偐傞梊憐偱偡偹丅
| HOME | backup偵栠傞 | 儕儞僋尦偵栠傞 |
彮偟偢偮夵椙傪廳偹丄偄偮偺娫偵傗傜ver傕45偵乮壓恾乯丅戝偒側夵掶偑偁偭偨偲偒偵侾侽寘戜傪曄偊偰偄傞偺偱丄
係俆夞傕夵掶偟偰偄傑偣傫偑丄埲慜偲斾妑偟偰夋柺傕曄傢傝揑拞惛搙偑忋偑偭偰偒偨偲巚偄傑偡丅
仾偙傟偼奜偟偨梊憐偱偡丅抪傪偝傜偡偨傔偵椺偲偟偰偲傝偁偘傑偟偨丅梸挘偭偰曃岦偑偐偐偭偰偄傞偙偲偑傛偔暘偐傞梊憐偱偡偹丅
搶嫗嫞攏応偱偼丄俀丆俁拝偵曃嵎抣幚愌偺偄傑偄偪側攏偺曽偑柇枴偺條側婥偑偟傑偡丅 拞嶳偱偼曃嵎抣忋埵偑埑搢揑偵桳棙偱偡偑丄偦傟偑奐嵜抧偺摿惈偲偄偆偺偱偟傚偆偐丠
擭柧偗偺搶嫗奐嵜偱偼丄侾侽寧偐傜廤傔偨彑偪晧偗寢壥偺暘愅傪尦偵丄 乽俀揰梊憐偱侾侽侽丒侾侽侽侽枩墌攏寯乿傪栚巜偦偆偲巚偭偰偄傑偡丅 堦搙偱傕忋庤偔偄偭偨傜偙偙偱曬崘偟傛偆偲巚偄傑偡丅
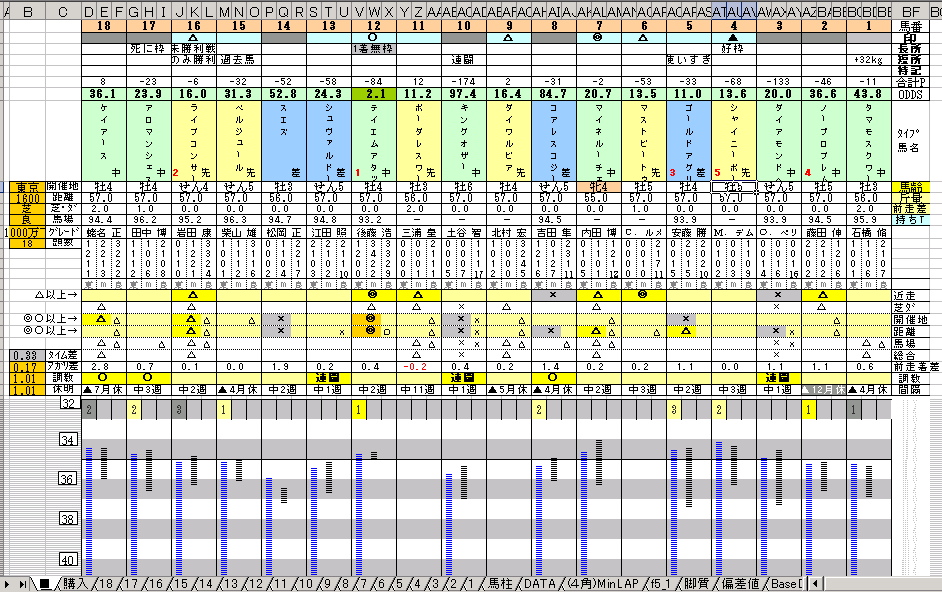
夋柺傪忋拞壓偵俁暘妱偟忋懁偵攏僨乕僞丄 拞抜偵曃嵎抣僨乕僞丄壓抜偼忋偑傝偺朹僌儔僼偵側偭偰偄傑偡丅
嶌傝棴傔偨僨乕僞傪尦偵丄孹岦傪挷傋偰傒傞偲丄 奐嵜抧丒嫍棧僨乕僞偱仢仜乮曃嵎抣65埲忋乯丄嬤嫷偱仮乮曃嵎抣55埲忋乯埲忋 偑昞帵偝傟偨応崌丄俁拝埲撪偵棃傗偡偄偙偲偑傢偐傝傑偟偨丅 傑偨丄亊乮曃嵎抣40埲壓乯偑晅偄偰偄傞攏偼傎偲傫偳棃偰偄側偄偙偲傕摿挜偱偡丅 乮椺偊偽搶嫗嫞攏応偱偼丄嬤嫷偱亊偑晅偄偨攏偼尰嵼傑偱偺帋峴偺寢壥偱偼侾摢傕棃偰偄傑偣傫丅乯 傑偨丄忋偑傝朹僌儔僼偱偼丄斣庤偑惍悢偱偁傞偨傔岆嵎偑戝偒偄偺偱偡偑丄 偦傟偱傕忦審偑忋偑傞偵廬偄丄侾昩埲忋偺奐偒偺偁傞嵎偑媡揮偟偵偔偔側傝傑偡丅 偝傜偵寚揰偲偟偰丄壓埵偺曽偱偼丄僨乕僞偺曣悢偺彮側偝偐傜惛搙偑奿抜偵棊偪傑偡丅
捈慄偺嫍棧傗嶁偺搊嶁搙偵傛偭偰帺摦偱曗惓傪偐偗傜傟傟偰乮偐偮惓偟偄寢壥偑摼傜傟傟偽乯 桳椏斉偵懟怓側偄傕偺偵側傞偺偱偟傚偆偑丄崱偺ver偱傕嬻僼傽僀儖偺忬懺偱栺10MB傕偁傝丄 偦偆偄偭偨婡擻傪晅偗傞傛傝傕丄尰忬偱岆嵎偺弌傗偡偄僨乕僞偲弌偵偔偄僨乕僞傪棟夝偡傞偙偲偺曽偑 桳堄媊偩偲巚偭偰偄傑偡丅
偙偆偄偭偨偙偲傪傆傑偊偰丄1000枩壓埲忋偺儗乕僗傪 専摙偺懳徾偲偟丄擖椡傪峴偭偰偄傑偡丅偡傞偲侾擔俀乣俁奐嵜偱俉乣侾侽儗乕僗掱搙偑岓曗偵嫇偑傝丄 偝傜偵乮攦偄栚傪尭傜偡偨傔濨枂側僨乕僞偼幪偰傞栚揑偱乯曃嵎抣偱仢仜偑弌側偐偭偨傕偺偵偮偄偰偼懳徾奜偲偟偰偄傞偺偱丄 幚嵺偵偼侾擔摉偨傝係乣俆儗乕僗偑専摙懳徾偲側傝傑偡丅
曃嵎抣偺巇慻傒忋丄弌応攏偑梋傝偵擇嬌壔偟偰偄側偄尷傝仢仜偑晅偔攏偼 懡偔偰俁摢傑偱偵尷傜傟傞偺偱丄嬤嫷忬嫷乮仮埲忋乯傗 奐嵜忦審偺榞傗揥奐宆偐傜幉傪寛掕偟傑偡丅
偙偙偱丄俁楢暋偱偁傟偽 偁偲偼岲傒偵傛偭偰偱偡偑憡庤傪俀揰拪弌偟俆揰掱搙傊棳偣偽寁侾侽揰偲側傝傑偡丅 偟偐偟丄俁楢扨偲側傞偲榖偑曄傢傝傑偡丅扨弮偵尵偭偰俁楢暋偺俇攞偺攦偄栚偑偁傞偐傜偱偡丅 幚嵺偵偼僴儞僨愴偱側偄尷傝仢仜偱慖戰偟偨攏偼楢懳偟傗偡偄孹岦偑偁傝傑偡丅 乮媡偵僴儞僨愴偱偼桪廏側攏偲偟偰僩僢僾僴儞僨傪偟傚偭偰偄傞偙偲偑懡偔丄俁拝傕傑傑尒傜傟傑偡丅乯
偙偙偐傜偼俰俼俙偺僒僀僩側偳偱愴楌傪妋擣偟 戝傑偐偵尵偭偰乽係丒侽丒侽丒俇乿宆偐乽俀丒俁丒俀丒俁乿宆偺偳偪傜偵奩摉偡傞偐妋擣偟傑偡丅 慜幰側傜侾拝屌掕丄屻幰側傜俀拝屌掕 偵偟傑偡丅屻幰偼媗傔偑娒偔側傞僞僀僾偱丄恖婥偵側偭偰偄傞応崌俀拝屌掕偺曽偑柇枴偑偁傝傑偡丅
ver10戜偺曃嵎抣偲斾妑偟偰曄偊偨揰偼丄庤擖椡偐傜僐僺儁傊曄峏偟偨偙偲偑尨場偱丄 慡僨乕僞偺拞偐傜昁梫側忦審偺傒傪拪弌屻偵丄曣悢偱妱偭偨抣傪斾妑偟偰偄傞偙偲偱偡丅
岞幃僒僀僩偱慡僨乕僞傪尒側偑傜巜愜傝偱悢偊忋偘偰偄偔偲娫堘偄偑婲偒傗偡偔丄帪娫傕朿戝偵偐偐傞偨傔丄 僐僺儁宆傊曄峏偟傑偟偨偑丄僨乕僞憖嶌傪忋庤偔傗傜側偄偲拪弌偱偒傑偣傫丅
巹偺応崌偼丄儁乕僕偺昁梫側晹暘傪慖戰屻僐僺乕偟丄乽僥僉僗僩宆乿偲偟偰僄僋僙儖偵揬晅傑偡丅 偙偆偡傞偲侾峴暘偺僨乕僞偑侾偮偺僙儖偵慡偰彂偒崬傑傟傑偡丅杮棃倂俤俛僒僀僩偱偼乽昞乮table乯乿僨乕僞偱偁偭偨僙儖娫偼 敿妏嬻敀側偳偱嬫愗傜傟傑偡丅敿妏嬻敀偺屄悢偑忬嫷偵傛偭偰堎側傞偨傔EXCEL娭悢偺乽TRIM乿傗乽CLEAN乿傪棙梡偟偰 晄梫側嬻敀傪徚偟偰丄昁偢娷傑傟傞乽奐嵜抧乿側偳偺暥帤偺埵抲偐傜 昁梫側僨乕僞傪嶲徠偝偣偨偄僙儖偵棊偲偟崬傓條偵偟偰偄傑偡丅
奜崙奐嵜傗抧曽奐嵜偱偼僨乕僞悢偑懌傝偢僄儔乕傪婲偙偡偺偱丄僄儔乕旔偗偵乽峴偺桳岠惈乿傪敾抐偝偣傞偙偲偑昁梫偱偡丅 乮桳岠側抣偑擖偭偰偄傟偽侾丄擖偭偰偄側偗傟偽侽偲偡傞if娭悢傪暿僙儖偵嶌傝丄慡偰妡偗崌傢偣偰寢壥偑侾側傜桳岠乯
僨乕僞傪惍棟偟廔傢偭偨傜丄拪弌嶌嬈偱偡丅僩僢僾僔乕僩偵摉奩儗乕僗偺 奐嵜抧傪慖戰偡傞崁栚偑偁傞偺偱偡偑乮乽儕僗僩偐傜慖戰乿婡擻傪巊偭偰俰俼俙慡奐嵜抧傪慖戰偱偒傞傛偆偵偟偰偁傝傑偡丅乯 摉慠堦抳偡傞応崌偺僨乕僞偼拪弌偟傑偡偑丄偝傜偵Vlookup娭悢傪巊梡偟偰嵍塃傗嬤帡嫍棧偺僨乕僞傕 僒僽僙儖偵昞帵偱偒傞傛偆偵側偭偰偄傑偡丅
偙傟偼丄庢幪慖戰偺帪偵嵟傕崲傞"桳柤攏"偺弶僐乕僗 偺嶲峫偲偟偰嬤帡僨乕僞傪摼傞偨傔偱偡丅 乮婎杮揑偵偼丄偦偆偄偭偨攏偼慖戰偟側偄傛偆偵偟偰偄傑偡偑丅 挿偄栚偱尒傞偲妱偵崌傢側偄偺偱丅乯
僨乕僞拪弌忋偱敾抐偑暘偐傟傞偺偼丄僨乕僞偺曣悢偱妱傞偐妱傜側偄偐偱偡丅 偪側傒偵曣悢偱妱傞偲Average偑摼傜傟傑偡丅
摉奩忦審偑宱尡朙晉側傜摉慠僨乕僞悢傕懡偔側傝傑偡丅奐嵜抧丒嫍棧丄 偙傟偼崱偺偲偙傠曣悢偱妱偭偰偄傑偣傫丅嬤憱 僨乕僞偼曣悢偱妱偭偰偄傑偡丅抧曽奐嵜側偳偱僄儔乕偑 弌傞応崌偑懡偔丄曣悢偱妱偭偨曽偑乮宱尡懃偱乯桪椙側僨乕僞偑摼傜傟偰偄傞偐傜偱偡丅
偙傟傕敿暘偼帺摦拪弌偱偡丅 拞墰偺朹僌儔僼Ave娭學偼慡帺摦壔偟偰偁傝傑偡丅柺搢側偺偱丅
係妏斣庤亐俀亄忋偑傝僞僀儉偱寁嶼偟偰偄傑偡丅係妏埵抲傪捠忢攏恎嵎偱峫偊傞傋偒強傪丄 扨弮壔偟偰偄傞偺偱岆嵎偑偁傝傑偡丅
嵍懁偼嵟懍乮偱偼側偄偑乯憐掕忋偑傝抣偱偡丅 拪弌偝傟偨忋偑傝僞僀儉偐傜Min娭悢偱嵟彫抣傪慖傃丄摉奩儗乕僗偺奐嵜擔傪昞帵偝偣傑偡丅 岞幃僒僀僩偱摉奩擔傪挷傋係妏偺埵抲偩偗 擖椡偡傟偽傛偄傛偆偵偟偰偁傝傑偡丅乮庤擖椡売強偼側傞傋偔彮側偔!乯
塃懁偼傎偲傫偳嬻敀朹僌儔僼偱偡偑丄偙偙偵偼弶僐乕僗攏梡偺 嬤帡僨乕僞傪擖椡偡傞偲昞帵偝傟傞巇慻傒偵側偭偰偄傑偡丅 俰俼俙僒僀僩偱慖戰偟偨侾儗乕僗傪俀夋柺暘僐僺儁偟丄係妏埵抲傪擖椡偡傞偲昞帵偝傟傑偡丅
偄偢傟偵偟偰傕攏恎嵎仺昩偺曄姺傪峴偭偰偄傞偺偱 偦偺帪揰偱岆嵎偑惗偠偰偄傑偡偟丄 忢偵嵟崅偺忬嫷偱攏偑憱傟傞傢偗偱傕側偔丄偝傜偵尵偊偽媡偵埲慜傛傝傕椙偄僞僀儉傪偨偨偒弌偡壜擻惈傕偁傞傢偗偱 丄婎杮揑偵偼懌愗傝梡乮侾乣俀昩嵎乯偲妱傝愗偭偰偄傑偡丅
| HOME | backup偵栠傞 | 儕儞僋尦偵栠傞 |